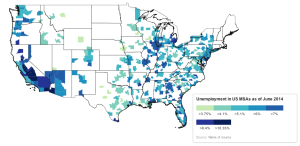
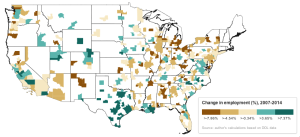
I have created two choropleth maps of the state of employment in US metropolitan statistical areas (MSAs). The first map displays the unemployment rate in about 380 US MSAs. The second displays the percent change in employment (not unemployment) between June of 2007 (before the recession began) and June of 2014 (latest available data). To make the maps a little clearer, I’ve included state and coastal boundaries.
I used data from the BLS (http://www.bls.gov/lau/metrossa.htm), a shapefile from the US Census (https://www.census.gov/geo/maps-data/data/tiger.html), fussed with the data in various spreadsheet programs, and then plugged these variously into QGIS, TileMill, and MapBox Studio. The maps here are a final product of MapBox.
I’d like to able to create and share maps here without always going into the methodology. I add two notes about methodology here that are rather important before discussing the substance of the maps.
Map-maker, map-maker, make me a map
I’ll be the first to admit that my maps are an example of terrible cartography. Part of this comes from my technical inaptitude, but part comes from the decision to look at MSAs. In theory, metropolitan areas are a useful unit to study the structure of economy, but, practically, few people are familiar with their size, boundaries, relative location, and even constituent units. This lack of familiarity with the MSA is compounded by the fact that the unit is not defined in much of a standardized way. For example, Los Angeles MSA consists only of Los Angeles and Orange counties, its population was approx. 12 million in 2010, and its area is 4,850.3 sq. mi., according to Wikipedia. New York MSA, by contrast, consists of 25 counties in over three states, its population was close to 20 million in 2012, and its area is 13,318 sq. mi., also according to Wikipedia. So, we’re dealing with fairly arbitrary statistical creations.
While it may be difficult for most people to really read these maps (that is, to determine what the exact figures are for each and every MSA on the map), there are other patterns that can be picked up on more easily. One example is clustering of similar levels of unemployment and employment change at various scales: within-states or between them, or across larger regions. In my view, the map is not necessarily the final output; it is descriptive, not explanatory. These maps are meant to provide a basic snapshot and starting point for additional, more specific analysis.
And the lights all went out in Massachusetts
You might notice that no MSA located in the New England states is displayed. This absence comes from at least three quirks in US government statistics, which are worth mentioning for the important limits they impose on the maps. First, there aren’t actually any “MSAs” in New England; they are called “New England City and Town Areas (NECTAs).” This immediately introduces some confusion and if you dig around the Census, Bureau of Labor Statistics (BLS), and other US government sources, you’ll notice that New England states, and Massachusetts especially, consistently make odd appearances in federal statistics (often times, figures for these areas are not reported at all, or have a significant delay in their release). I’m not sure what’s going on here. As a result, we lose valuable information especially on Boston, one of the largest US cities, and Connecticut, which contains quite a bit of the US financial and insurance industry.
Second, the shapefiles I used to create the maps use “core based statistical area (CBSA),” which differ somewhat from MSAs. The two units are quite similar. CBSAs are typically amalgamations of “micropolitan” and “metropolitan” areas. The distinction is that metropolitan areas possess a population greater than 50,000. There are over 500 micropolitan areas and around 350 metropolitan areas. The employment data (retrieved from the BLS via the Department of Labor), it seems, covers mainly metropolitan and not micropolitan areas. Although, one of the key problems maybe that the BLS data is in fact organized according to MSAs, whereas the shapefile is organized by CBSA.
Again, the trade-off in using urban-level economies is that the way the data are organized and collected is something of a mess. I think, however, that looking at states does not give the same picture of activity, and nor do counties. And, more importantly, I’m not attempting to be too scientifically rigorous right now.
Final caveat: the maps display only the lower 48 states.
The substance
Let’s begin with the distribution of unemployment as of June 2014. The worst-performing areas are located in Oregon, California, Arizona, around the Great Lakes (particularly around in Illinois and Michigan), and the southern states (particularly Alabama, Georgia, and Florida). There are several clusters of contiguous metro areas where unemployment is concentrated, including California’s Central Valley, the US-Mexico border region in the southwest, the greater Chicago, Detroit, and Atlanta areas, and also the southern tip of New Jersey (Atlantic City). The best-performing areas include Salt Lake City, the large cities of Texas (San Antonio, Dallas, Houston), and metro areas in Oklahoma, Louisiana, Iowa, Minnesota, and South Carolina.
A few features stand out. First, city size does not imply better or worse unemployment prospects(Chicago and New York versus Houston and Washington, DC, for instance). Perhaps this has to do with the specialized industrial and commercial base of individual areas.
Second, though statistical analysis could analyze this more precisely, just eyeballing the map suggests that the level of variation within states is less than the level of variation between states. That is, there is probably an independent effect of US states, possibly related to differences in state/municipal public spending/austerity, state tax regimes, or to the disproportionate allocation of federal aid to the states. Doing an econometric analysis of metropolitan performance is made trickier when using states as an independent effect, because so many MSAs located on and east of the Mississippi sit in more than one state.
Third, it is apparent that there are regional patterns; that is, some patterns appear consistent across many states. There seem to be three main groups. First, the west coast states as well as Nevada and Arizona; second, the Great Lakes area; and third, the southeast. Possible explanations for the first and third are the high concentration of distress from the collapse in real estate and banking (in the west coast, thrift) markets. Indeed, some of the largest bank failures of the 2008-2010 period were west coast-based savings institutions (IndyMac, Wachovia). Economic structure may also be a factor, such as the high level of specialized industrial activity as a share of total activity in the Great Lakes. However, I was under the impression that California, Georgia, and Florida are actually quite diversified economies (agriculture, industry, FIRE, professional services). Diversity ostensibly delivers greater resilience to economic downturns. So, this issue needs to be fleshed our more.
The next map displays a very different set of dynamics. Where unemployment provides an indication into the mismatch between the civilian population able and willing to work and the supply of jobs, employment growth is actually quite different. At the macro-level, employment growth reflects demographic change, business sentiment, consumer preferences, the savings rate, and there is also an important sectoral component.
This difference in the underlying dynamics explains why unemployment can remain very high, such as in the California Central Valley area, while employment growth is actually expanding. We require more regional- and sectoral-specific data to test whether this discrepancy arises from a skills mismatch (for example, a hypothesis could be that professional or information sectors are expanding while the construction or agriculture industries continue to contract, leaving the comparatively under-skilled workers in the latter unprepared for work in the former) or perhaps because of austerity measures that rationalized the public sector, or perhaps some other hypothesis.
At the very least, we have a reinforced sense of the regional patterns of growth and contraction. Texas, Louisiana, and, to an extent, Oklahoma are growing–this region is one of the main sites of the mineral extraction-natural gas-shale fracking boom of the last few years. The former industrial heartlands continue their long-term process of collapse. The greater New York area registers a contraction, although it seems the worst of it was pushed to the more peripheral areas in New Jersey, Pennsylvania, and the New York suburbs as opposed to the core area. The Washington, DC area–dare we go so far as to include Richmond, VA here?–is booming, so at least austerity has been good to some people.
Bottom line
There are two chief points I’d like to make, unrelated to the specific content of the maps. First, I think one of the next steps is a set of exploratory econometric analyses that can test the effect of states, proximity between metropolitan areas, industrial structure, and metro-level real estate and housing market distress during the Great Crash of 2007-2009. Cluster-based analytical techniques would also be a useful way of identifying patterns, although neither econometric analysis nor cluster techniques reveal much in the way of explanation.
Second, to get at the causes of differential economic performance would require a series of case studies. An appropriate scale for such case studies, I suggest, is “regional”: not necessarily an entire state, but not necessarily only the areas within a state. Again, cluster-based techniques might be a good first step in deciding which areas are similar or distinct enough to merit study as a group. Interestingly, the Federal Reserve regional banks are a fairly reliable source of this kind of study–each Fed region is composed of three or so states, and every now and then their economists produce a report of regional conditions.






